-
正则表达式与 grep
- 注意事项
- 基础正则与实战
- 扩展正则与实战
-
三剑客 sed
1. 正则
📢 注意事项
- 英文字符
1.1 符号概述
| 正则表达式 | |
|---|---|
| 基础正则 | ^ $ . * .* [] [^] |
| 扩展正则 | ` |
| 其他类型正则 |
1.2 基础正则
三剑客命令默认支持的正则
^ 以…开头的行

$ 以…结尾的行
-
以数字 6 结尾

-
以字母 m 结尾

-
cat -A 显式出隐藏的字符
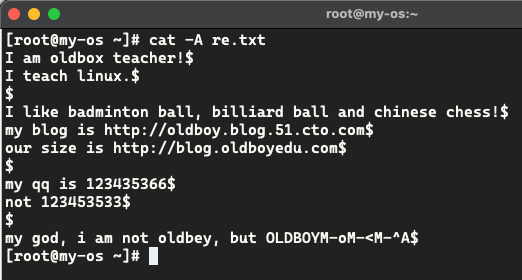
^$ 空行,这行中没有任何字符
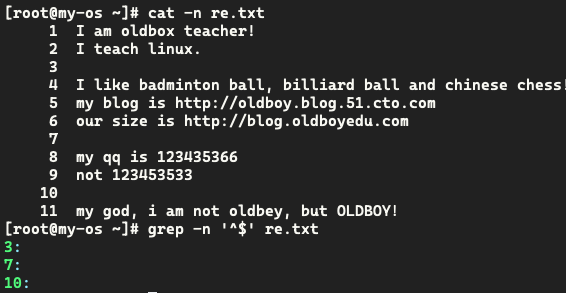
排除空行
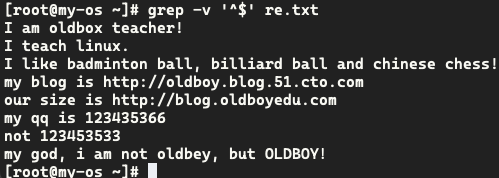
用于排除文件中的空行,排除空行和带井号的行
. 任意一个字符
-
oldb任意一个字符y

了解:. 过滤的时候会排除空行,. 不会匹配空行
\ 转义字符
找出以 . 结尾的
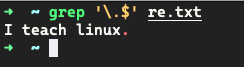
* 匹配多次
前一个字符连续出现 0 次或 0 次以上
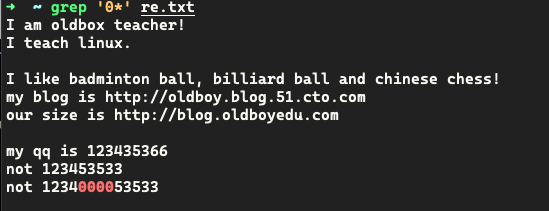
.* 所有
点表示任意字符,星号表示多个,所以.*表示所有字符

贪婪:正则表示连续出现的时候,表示所有的时候,体现出贪婪性
-
匹配开头一直到 o 的内容
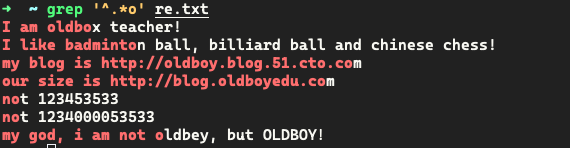
[] 匹配任意一个字符
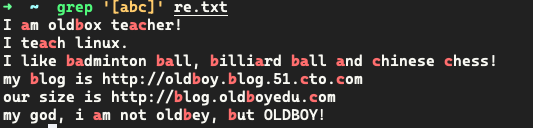
[abc] 表示匹配任意一个字符,a 或 b 或 c,中括号相当于一个字符
-
匹配数字
1grep '[0-9]' re.txt -
匹配小写字母
1grep '[a-z]' re.txt -
匹配大写字母
1grep '[A-Z]' re.txt -
匹配大小写字母
1grep '[a-zA-Z]' re.txt -
匹配大小写字母+数字
1 2grep '[a-zA-Z0-9]' re.txt grep '[0-Z]' re.txt -
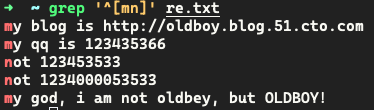
匹配出以字母 m 或 n 开头的行
-
匹配出以 . 或空格或!结尾的行

[ ] 会自动去掉符号的特殊含义
[^] 取反
[^abc] 表示匹配任意 1 个字符,排除 abc,中括号相当于一个字符
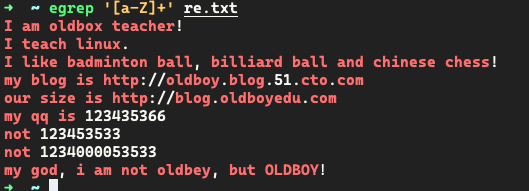
小结
| 基础正则 | 含义 |
|---|---|
| ^ | 以xxx 开头的行 |
| $ | 以…结尾的行 |
| ^$ | 空行 |
| . | 任意一个字符 |
| \ | 转义字符 |
| * | 前一个字符出现0 次或多次 |
| .* | 所有 |
| [ ] | 匹配括号中的一个字符 |
| [^] | [^abc] 匹配除了 abc 之外的内容 |
1.3 扩展正则
- egrep 或 grep -E
- sed使用 sed -r 支持扩展正则
- awk 默认支持扩展正则
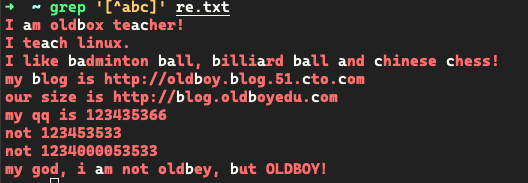
+ 前一个字符连续出现 1 次或以上
+大部分配合[ ]使用
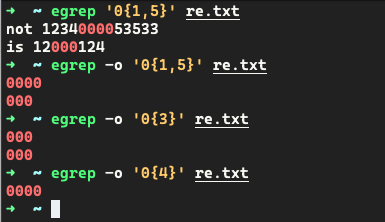
-
取出连续出现的 0
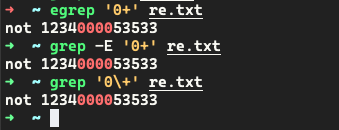
-
取出连续出现的数字
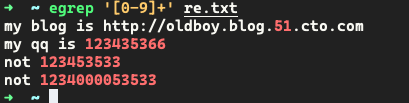
-
取出连续出现的字母

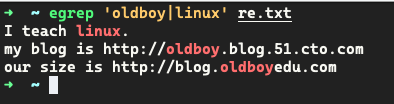
| 或者
-
文件中包含 oldboy 或linux 的
-
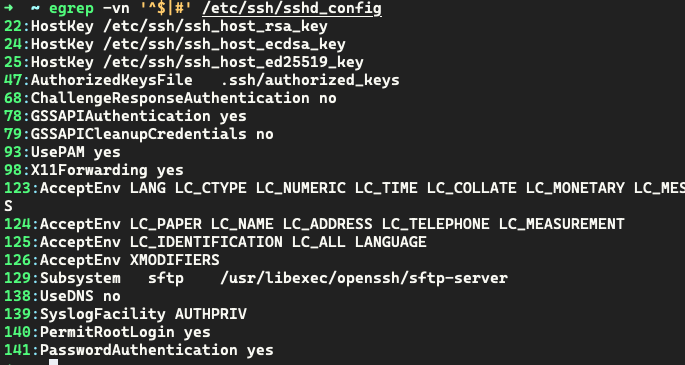
排除/ect/ssh/sshd_config 中的空号或者注释行,输出显式行号
() 表示一个整体,用于后向引用(反向引用 sed)

{} 大括号
a{n,m} 前一个字符连续出现至少 n 次,最多 m 次
| 格式 | 解释 |
|---|---|
| a{n,m} 前一个字符连续出现至少 n 次,最多 m 次 | 表示连续出现的范围 |
| a{n} 前一个字符连续出现n 次 | 匹配固定的次数 |
| a{n,} 前一个字符至少连续出现 n 次 | |
| a{,m} 前一个字符连续出现,最多 m 次 |
匹配身份证的正则:
分析:前 17 为为数字,后一位为数字或为 X

? 前一个字符出现 0 次或 1 次

小结
| 扩展正则 | 含义 |
|---|---|
| + | 前一个字符连续出现 1 次或多次 |
| | | 或者 |
| ( ) | 🅰️ 表示整体,🅱️ 后向引用或反向引用(sed) |
| { } | a{n,m} 前一个字符连续出现至少 n 次,最多 m 次 |
| ? | 前一个字符出现 0 次或 1 次 |
1.4 perl 语言正则
| 符号 | 含义 |
|---|---|
| \d | [0-9] |
| \s | 匹配空字符 空格、tab 等 |
| \w | [0-9a-zA-Z_] |
| \D | [^0-9] 排除数字 |
| \S | 非空字符 |
| \W | 排除数字、字母和_ |
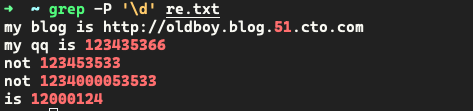
1.5 零碎的正则
2. sed
2.1 概述
- 取行,过滤,替换修改文件内容
- 后向引用
2.2 格式
| sed | 选项 | ‘条件动作’ | 文件 |
| ‘找谁干啥’ |
| 选项 | 说明 |
|---|---|
| -n | 取消默认输出 |
| -r | sed支持扩展正则 |
| -i | 修改文件内容,这个选项放在最后 |
| -i.bak | 先备份在修改,这个选项放最后 |
2.3 如何运行
- 模式空间:容纳当前行的缓冲区,即通过
模式匹配到的行被读入该空间中 - 保持空间:一个辅助缓冲区,可以和模式空间进行交互(通过h,H,g,G),但命令
不能直接作用于该空间,在进行数据处理时作为“暂存区域”
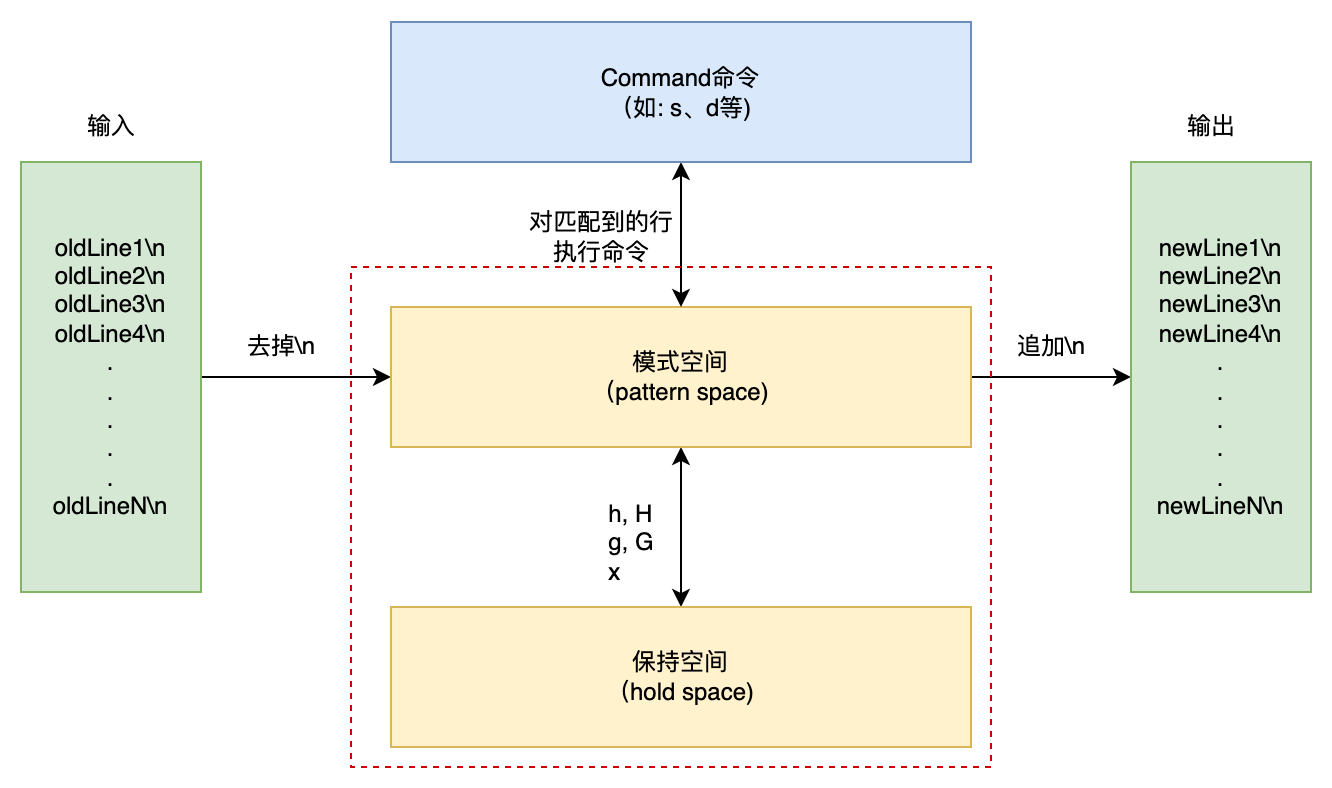
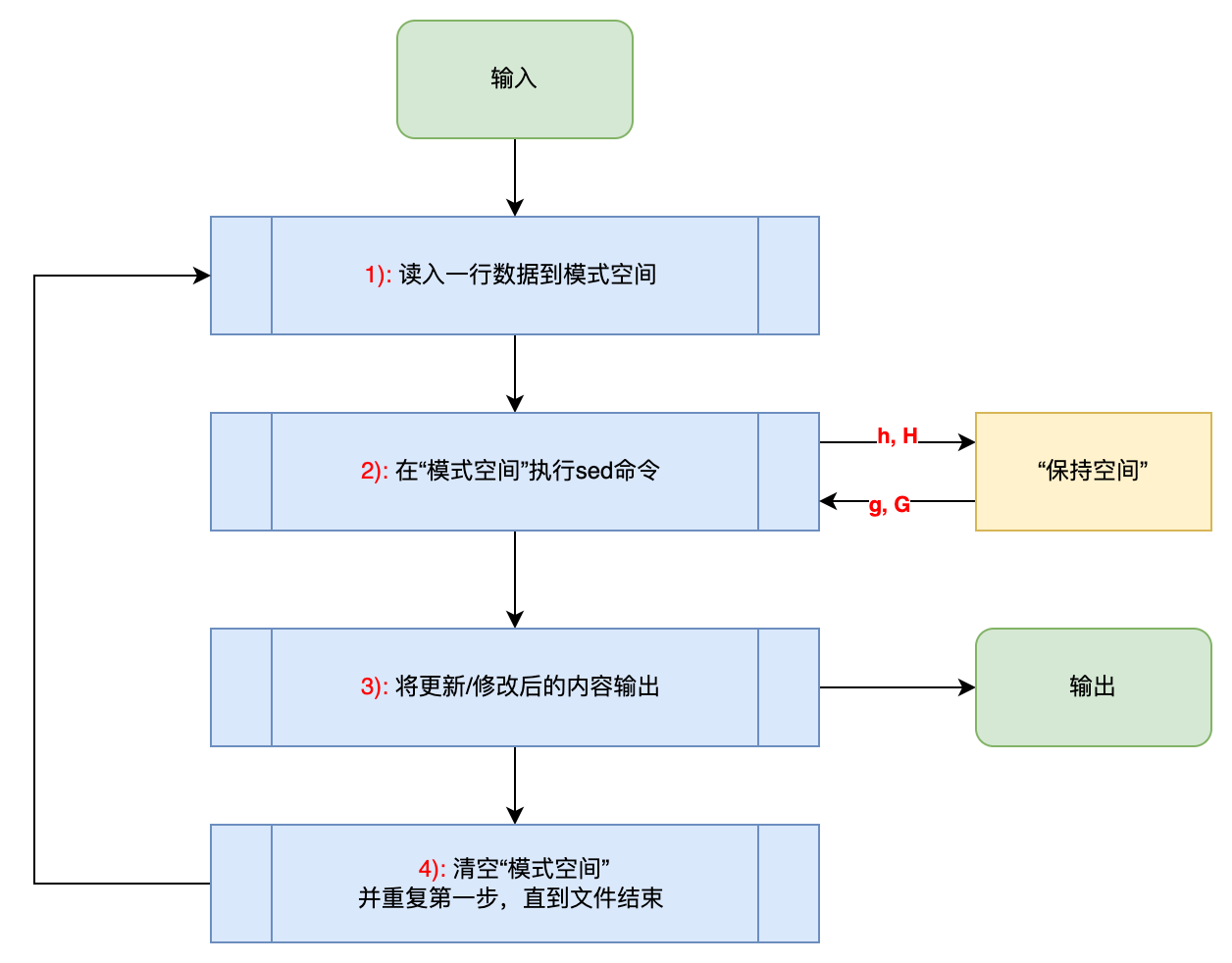
执行步骤:
1)读入一行数据到模式空间
2)在模式空间执行sed命令
3)将更新/修改后的内容输出
4)清空模式空间,并重复第一步,直到文件结束
2.4 sed 增删改查之查找
- 类似grep 命令的过滤,比 grep 强在可以指定行号
- 类似于 grep 命令的功能,模糊查询(通过正则)
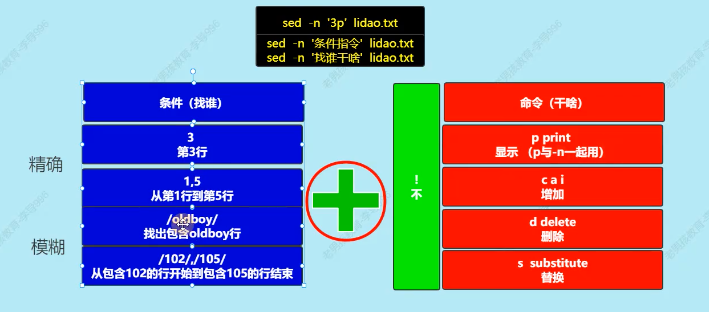
案例 1: 取出文件第三行

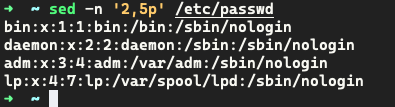
案例 2:取出/etc/passwd的第2行到第5行
案例 3:过滤出/etc/passwd中包含root 的行
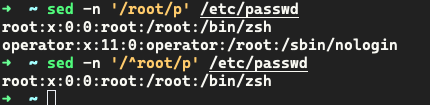
sed 进行过滤的时候需要使用// 并且里面支持基础正则
如果需要使用扩展正则则需要使用 sed -r 选项
案例:获取范围内的日志
|
|
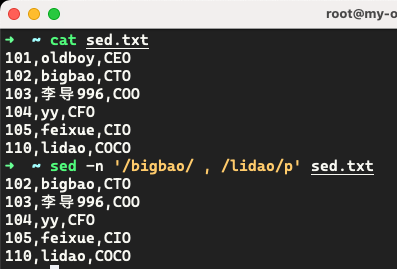
案例:取出 access.log 过滤出 11:05 到 11:06分的日志
|
|
案例:只显示第 2 行和第 5 行
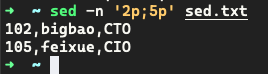
案例:表示有规律的查找
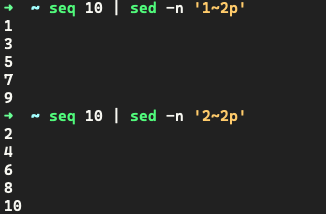
2.5 sed 增删改查之修改
- sed 的修改叫做替换
- sed 默认不修改,加上 -i 选项能修改
-
案例:把 sed.txt 文件中 lidao 替换为 oldboy
1sed 's#lidao#oldboy#g' sed.txt1 2 3 4sed 's###g' sed.txt sed 's#找谁#替换成什么#g' sed.txt s substitute 替换 g global 全局替换 这一行中把所有匹配到的内容全都进行替换,否则只替换每一行第一个匹配的内容1 2 3 4 5 6 7 8 9 10 11 12 13 14➜ ~ sed 's#[0-9]##g' sed.txt # 将数字替换为空 ,oldboy,CEO ,bigbao,CTO ,李导,COO ,yy,CFO ,feixue,CIO ,lidao,COCO ➜ ~ sed 's#[0-9]##' sed.txt 01,oldboy,CEO 02,bigbao,CTO 03,李导996,COO 04,yy,CFO 05,feixue,CIO 10,lidao,COCO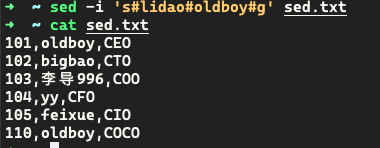
sed 命令替换的时候 s###g
也可以写为 s@@@g s///g
-
修改文件内容之前进行备份,然后修改文件内容
1sed -i.bak 's#bigbao#oldbao#g' sed.txt
2.6 增删改查之替换
123456 加上<> 变成<123456>
|
|
\1 表示前面(.*)中匹配到的内容 ()小括号表示分组 \1 表示取出第一组的内容, -r 表示用到扩展正则
-
给每个数字都加上<>
1 2 3 4➜ ~ echo 123456 | sed -r 's#([0-9])#<\1>#g' <1><2><3><4><5><6> ➜ ~ echo 123456 | sed -r 's#(.)#<\1>#g' <1><2><3><4><5><6>
后向引用格式
应用说明:
sed 命令用于处理列的方式。
使用格式:
使用替换的形式 s###g
前两个井号之间通过正则加小括号,进行分组,
后两个井号之间通过 \数字 获取前面分组的内容,
整体是后面调用前面分组的内容,所以称之为反向引用(后向引用)
案例
-
调换 /etc/passwd 第一列和最后一列的内容
1 2 3 4 5root:x:0:0:root:/root:/bin/zsh bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin1sed -r 's#(^.*)(:x.*:)(.*$)#\3\2\1#g' passwd -
取出网卡 ip 地址
1 2 3 4 5 6 7 8 9 10 11➜ ~ ip a s eth0 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether 00:16:3e:2f:45:fa brd ff:ff:ff:ff:ff:ff inet 172.18.243.120/20 brd 172.18.255.255 scope global dynamic eth0 valid_lft 313947416sec preferred_lft 313947416sec inet6 fe80::216:3eff:fe2f:45fa/64 scope link valid_lft forever preferred_lft forever ➜ ~ ip a s eth0 |sed -n '3p' inet 172.18.243.120/20 brd 172.18.255.255 scope global dynamic eth0 ➜ ~ ip a s eth0 |sed -n '3p' | sed -r 's#^.*inet (.*) brd.*$#\1#g' 172.18.243.120/20进阶:
1 2 3 4 5sed -n '3p' sed -r 's#^.*inet (.*) brd.*$#\1#g' --- sed -nr '3 s#^.*inet (.*) brd.*$#\1#g p' -
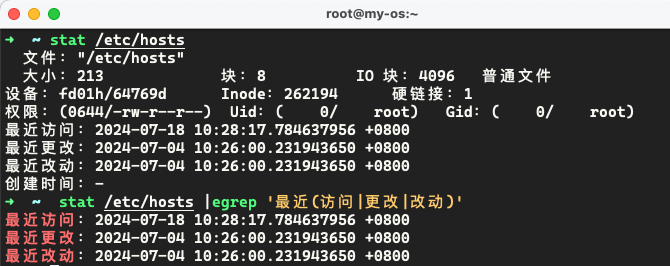
取出 stat /etc/hosts 中的 0644 或 644
1 2 3 4 5 6 7 8 9 10 11 12➜ ~ stat /etc/hosts 文件:"/etc/hosts" 大小:213 块:8 IO 块:4096 普通文件 设备:fd01h/64769d Inode:262194 硬链接:1 权限:(0644/-rw-r--r--) Uid:( 0/ root) Gid:( 0/ root) 最近访问:2024-07-20 10:28:17.784713652 +0800 最近更改:2024-07-04 10:26:00.231943650 +0800 最近改动:2024-07-04 10:26:00.231943650 +0800 创建时间:- ➜ ~ stat /etc/hosts | sed -nr '4 s#^.*\((.*)/-rw.*$#\1#g p' 0644
2.7 增删改查之删除
- d sed 命令删除功能按照 行 为单位进行
- 如果仅仅删除某一行的一些字符推荐使用 ’s###g'
|
|
排除/删除 文件中的空行和带注释的行
|
|
2.8 增删改查之增加
-
cai
-
a append 在指定行后追加
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15➜ ~ cat sed.txt 101,oldboy,CEO 102,oldbao,CTO 103,李导996,COO 104,yy,CFO 105,feixue,CIO 110,oldboy,COCO ➜ ~ sed '3a 1024,aszhc,ufc' sed.txt 101,oldboy,CEO 102,oldbao,CTO 103,李导996,COO 1024,aszhc,ufc 104,yy,CFO 105,feixue,CIO 110,oldboy,COCO -
i insert 在指定行上插入
-
c replace 替换指定行的内容
-
3. awk
单行脚本
- 取行
- 取列
- 混合取行列
- 判断与运算
- 数组
| 四剑客 | 特点 | 擅长 |
|---|---|---|
| find | 查找文件 | 查找文件 |
| grep/egrep | 过滤 | 过滤速度最快 |
| sed | 过滤、取行、替换、删除 | 替换,修改,取行 |
| awk | 过滤、取行、取列、统计计算、判断、循环… | 取行、取列、统计计算 |
- awk是一个语言,叫做单行脚本
2.1 概述
1. 格式
|
|
2. 执行流程
2.2 取行
-
取出/ect/passwd 的第一行
1awk 'NR==1{print $0}' /etc/passwd
NR:Number of Record 记录,行号
== 表示等于
{print $0}输出正好内容, $0 表示当前行的内容仅取行,可以简写为:
1awk 'NR==1' /etc/passwd
-
取出第 2 行到第 5 行的内容
1 2 3 4 5➜ ~ awk 'NR>=2 && NR<=5' passwd bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin>=表示大于等于&& 表示并
|| 表示或
| awk常用的运算符 | 说明 |
|---|---|
| ==、 != | 等于 |
| >、<、>=、<= | |
| && | |
| || |
-
过滤出/ect/passwd文件中包含 root 或 nobody的行
1 2 3 4 5➜ ~ awk '/root|nobody/' /etc/passwd root:x:0:0:root:/root:/bin/zsh operator:x:11:0:operator:/root:/sbin/nologin nobody:x:99:99:Nobody:/:/sbin/nologin nfsnobody:x:65534:65534:Anonymous NFS User:/var/lib/nfs:/sbin/nologin -
从包含 root 的行到包含 nobody 的行
1 2 3 4 5 6 7 8 9 10 11 12 13 14➜ ~ awk '/root/,/nobody/' /etc/passwd root:x:0:0:root:/root:/bin/zsh bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin sync:x:5:0:sync:/sbin:/bin/sync shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown halt:x:7:0:halt:/sbin:/sbin/halt mail:x:8:12:mail:/var/spool/mail:/sbin/nologin operator:x:11:0:operator:/root:/sbin/nologin games:x:12:100:games:/usr/games:/sbin/nologin ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin nobody:x:99:99:Nobody:/:/sbin/nologin -
小结
- awk + NR 取出指定的行,指定范围的行
- awk + // 过滤
- awk + 其他变量功能用于精确过滤
2.3 取列
-
使用 awk 取出 ls -lh 的大小列和最后一列
1 2 3 4➜ ~ ls -lh /etc/hosts |awk '{print $5,$9}' 213 /etc/hosts ➜ ~ ls -lh /etc/hosts |awk '{print $5,$NF}' 213 /etc/hosts
awk中, $数字 表示列,
$1表示第一列,$0表示当前这行
$NF最后一列NF Number of Field 每行有多少列
$(NF-1) 倒数第二列,用于行数太多,或者正序数无规律的情况
1ls -lh /etc/hosts |awk '{print $(NF-1)}' # 倒数第二列
-
取出/etc/passwd中第一列,第 3 列和最后一列
awk 取列的时候,默认是通过空白字符进行分割的
空白字符:空格,连续空格,tab 键
但是一些时候默认分隔符不够了,需要使用手动指定分隔符,通过-F 指定
选择分隔符建议:看你目标两边是啥
1 2 3 4 5 6 7 8 9 10 11 12➜ ~ awk -F':' '{print $1,$3,$NF}' passwd root 0 /bin/zsh bin 1 /sbin/nologin daemon 2 /sbin/nologin adm 3 /sbin/nologin ➜ ~ awk -F':' '{print $1,$3,$NF}' passwd|column -t root 0 /bin/zsh bin 1 /sbin/nologin daemon 2 /sbin/nologin adm 3 /sbin/nologin lp 4 /sbin/nologincolumn -t对齐 -
指定复杂分隔符取出 ip
1 2 3 4 5 6 7 8➜ ~ ip a s eth0 | awk 'NR==3{print $2}' 172.18.243.120/20 ➜ ~ ip a s eth0 | awk 'NR==3{print $2}' | awk -F'/' '{print $1}' 172.18.243.120 ➜ ~ ip a s eth0 | awk 'NR==3' | awk -F'[ /]' '{print $6}' 172.18.243.120 ➜ ~ ip a s eth0 | awk 'NR==3' | awk -F'[ /]+' '{print $3}' 172.18.243.120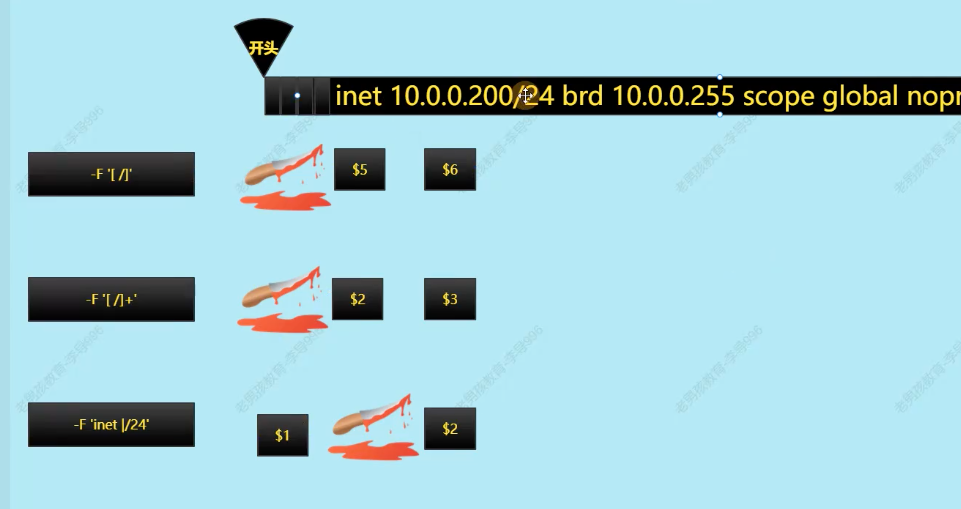
小结
- 如果是空格,连续空格,直接使用 awk 取列即可
- 其他情况需要通过 -F 指定分隔符加正则实现 []、 []+、 |
2.4 取行同时取列
-
取 ip 地址
1 2➜ ~ ip a s eth0 | awk -F'[ /]+' 'NR==3''{print $3}' 172.18.243.120 -
取出权限部分 stat /etc/hosts的 0644部分
1 2 3 4 5 6 7 8 9 10 11 12 13 14➜ ~ stat /etc/hosts 文件:"/etc/hosts" 大小:213 块:8 IO 块:4096 普通文件 设备:fd01h/64769d Inode:262194 硬链接:1 权限:(0644/-rw-r--r--) Uid:( 0/ root) Gid:( 0/ root) 最近访问:2024-07-21 10:28:17.784671787 +0800 最近更改:2024-07-04 10:26:00.231943650 +0800 最近改动:2024-07-04 10:26:00.231943650 +0800 创建时间:- ➜ ~ stat /etc/hosts | awk -F'[/(]' 'NR==4''{print $2}' 0644 ➜ ~ stat /etc/hosts | awk -F'[^0-9]+' 'NR==4''{print $2}' 0644 -
对列的判断,取出/etc/passwd 文件中第3列大于 1000的行,取出这一列,第 3 列和最后一列
- 条件:$3
- 动作:第 3 列和最后一列
1 2 3 4➜ ~ awk -F':' '$3>1000''{print $1,$3,$NF}' /etc/passwd nfsnobody 65534 /sbin/nologin ➜ ~ awk -F':' '$3>1000''{print $1,$3,$NF}' /etc/passwd|column -t nfsnobody 65534 /sbin/nologin通过 awk 实现对某一列进行判断
-
如果系统 swap 使用超过 0 则输出"异常系统开始占用 swap"
1 2➜ ~ free |awk '/Swap/ && $3>=0 {print "系统异常"}' 系统异常 -
过滤出/etc/passwd第 4 列的数字是以 0 或 1 开头的行,输出第 1、3列
- 之前^或$ 表示某一行的开头或结尾
- 在 awk 中因为 awk 可以取列,通过列可以过滤某一列中包含什么 ,过滤某一列中以xxx开头或结尾
1 2 3 4 5 6awk -F':' '$4 ~ /^[01]/' ➜ ~ awk -F':' '$4 ~ /^[01]/''{print $1,$3}' passwd root 0 bin 1 sync 5 shutdown 6awk 中,通过 $3 ~
- ~ 表示包含的意思,
$1 ~ /root/表示第一列中包含 root - !~ 表示不包含
小结
- 取行:
NR==1、NR>=1、$3 >=1000、$3 ~ /root/ - 取列:
$1、$NF、$(NF-1)
2.5 统计与计算
统计次数
- 仅仅需要统计出现了多少次,出现了多少个,可以使用 wc -l 方式
|
|
END{} 内容会在 awk 读取完文件的时候执行
END{} 一般用于输出执行结果
计算总和
|
|
总结
- awk 取行列
- awk 进行对列的比较大小
- awk 进行对列过滤
- awk 计算、求和
seq:输出数字序列
|
|