MySQL 怎么设置主从复制
-
修改配置文件
1 2 3[mysqld] log-bin=mysql-bin # 开启 binlog 日志 server-id = 1 # 指定服务器 id 为正整数 -
创建一个用于从服务器连接的用户,并授予复制的权限
1 2CREATE USER 'replica_user'@'%' IDENTIFIED BY '123456'; GRANT REPLICATION SLAVE ON *.* TO 'replica_user'@'%'; -
在从服务器上修改配置文件
1 2[mysqld] server-id=2 -
在 master 服务器上查看日志文件及位置
1 2 3 4 5 6mysql> show master status; +------------------+----------+--------------+------------------+-------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set | +------------------+----------+--------------+------------------+-------------------+ | mysql-bin.000001 | 603 | | | | +------------------+----------+--------------+------------------+-------------------+ -
在slave上配置主从同步的信息的哪个位置开始同步
1 2 3 4 5 6 7CHANGE MASTER TO MASTER_HOST='10.10.10.11', MASTER_USER='replica_user', MASTER_PASSWORD='123456', MASTER_LOG_FILE='mysql-bin.000001', MASTER_LOG_POS=603; start slave; # 启动主从关系 -
查看从服务器的状态
1show slave status
或者采用GTID 的方式
drop,delete和truncate删除数据的区别?
- delete 语句执行删除是每次从表中删除一行,并且同时将改行的删除操作作为事务记录在日志中保存以便进行回滚。
- truncate 则是一次从表中删除所有的数据并不把单独的删除操作记录计入日志,删除行是不能恢复的。执行速度很快
- drop 是将表所占的空间全部释放掉。
在删除速度上, drop>truncate>delete
MySQL 主从复制原理
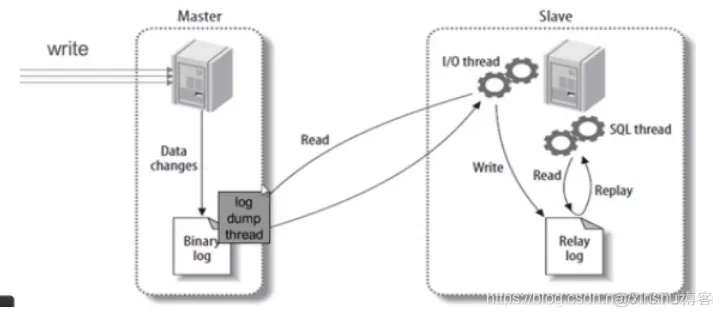
- 主服务器上:binlog dump 线程:负责发送 binlog
- 从服务器上:I/O线程,SQL 线程
主从复制存在哪些问题
mysql主从复制存在的问题:主库宕机后,数据可能丢失,从库只有一个sql Thread,主库写压力大,复制很可能延时。
解决方法: 用半同步复制解决数据丢失的问题,用并行复制解决从库复制延迟的问题。
主从同步的延迟问题、原因和解决方案
判断主从延迟的方法:show slave status
-
从服务器配置过低导致延迟
从服务器上有两个线程,消耗只读节点的 IO 资源,所以如果配置不够会导致只读节点数据延迟
-
主库的 QPS 过高导致只读节点延迟
由于只读节点与主库的同步采用的是单线程同步,而主库的压力是并发多线程写入,这样势必会导致只读节点的数据延迟
解决办法:开启并行复制(多线程复制)
-
主库的 DDL 语句导致只读节点延迟
如果DDL操作在主库执行时间很长,那么同样在备库也会消耗同样的时间。
比如在主库对一张500W的表添加一个字段耗费了10分钟,那么在只读节点上也同样会耗费10分钟,所以只读节点会延迟600S
如果只读节点上有个执行时间很长的查询正在进行,那么这个查询会堵塞来自主库的 DDL,读节点表被锁,直到查询结束为止,进而导致了只读节点的数据延迟。
-
主库执行大事务导致延迟
主库执行了一条insert … select非常大的插入操作,该操作产生几个G的 binlog 文件,导致只读节点出现延迟
解决办法:拆解大事务为小事务。
为了避免 MySQL 主从复制延迟:
-
数据库设置主从同步加速
sync_binlog在slave端设置为0
禁用 slave 端的 binlog
-
架构方面:在架构上做优化,尽量让主库的DDL快速执行,尽量减轻数据库的压力
-
硬件方面
binlog 的格式
-
statement:
优点:记录的简单,内容少 ,节约了IO,提高性能 缺点:导致主从不一致
-
row:
优点:记录数据详细(每行),主从一致
缺点:占用大量的磁盘空间,降低了磁盘的性能
-
mixed:混合模式
结合了statement和row模式的优点,会根据执行的每一条具体的SQL语句来区分对待记录的日志形式。对于函数,触发器,存储过程会自动使用row level模式
一主多从的从库宕机,如何手工恢复?
重做 slave
网站打开慢,请给出排查方法,如是数据库慢导致,如何排查并解决,请分析并举例?
- 检查操作系统是否负载过高
- 登陆mysql查看有哪些sql语句占用时间过长,show processlist,慢查询日志;
- 用 explain 查看消耗时间过长的 SQL 语句是否走了索引
- 对 SQL语句进行优化,建立索引
MySQL 的日志
错误日志、查询日志、慢查询日志、binlog、中继日志、事务日志
数据库cpu飙升到500%的话他怎么处理?
当 cpu 飙升到 500%时,先用操作系统命令 top 命令观察是不是 mysqld 占用导致的,如果不是,找出占用高的进程,并进行相关处理
如果是 mysqld 造成的, show processlist,看看里面跑的 session 情况,是不是有消耗资源的 sql 在运行。找出消耗高的 sql,
看看执行计划是否准确, index 是否缺失,或者实在是数据量太大造成。
一般来说,肯定要 kill 掉这些线程(同时观察 cpu 使用率是否下降),等进行相应的调整(比如说加索引、改 sql、改内存参数)之后,再重新跑这些 SQL。
也有可能是每个 sql 消耗资源并不多,但是突然之间,
有大量的 session 连进来导致 cpu 飙升,这种情况就需要跟应用一起来分析为何连接数会激增,再做出相应的调整,比如说限制连接数等
MHA 的原理
- 监控:MHA持续监控MySQL主从复制的状态,以便及时发现和处理故障。
- 故障检测:当MHA检测到主节点故障时,它会启动故障转移过程。
- 选主:MHA会选择一个从节点作为新的主节点,这个节点拥有最新的数据。
- 数据同步:MHA会将其他从节点的数据同步到新的主节点,确保数据一致性。
- 切换:MHA会将所有对主节点的请求重定向到新的主节点,完成故障转移。
MHA+ProxySQL+Keeplived
mysql主从+keepalived+mha。mha负责mysql的状态监控和mysql的状态转移,然后keepalived负责VIP的浮动迁移
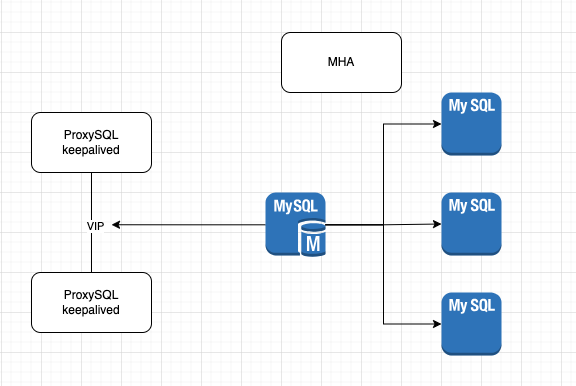
MHA Manager(1 台):
- 负责监控主库和从库的状态,并在主库故障时执行故障转移操作。可以与某个从库共享一台机器,但最好独立部署。
ProxySQL(至少 2 台):
- 代理数据库请求,实现读写分离和负载均衡。通常需要两台,以便通过 Keepalived 实现高可用性。
Keepalived(与 ProxySQL 部署在一起):
- Keepalived 通常与 ProxySQL 部署在同一台机器上,以管理虚拟 IP 的切换。因此 ProxySQL 的两台机器也会运行 Keepalived。