什么是布隆过滤器
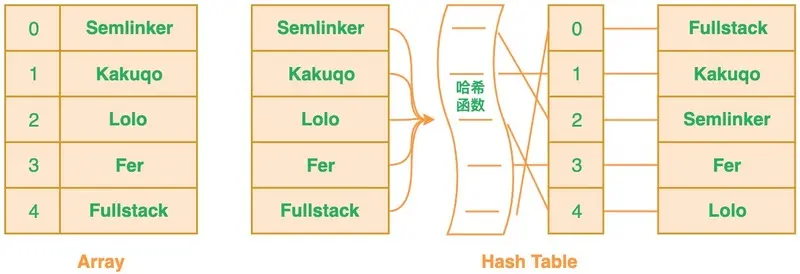
如果想要判断一个元素是不是在一个集合里,一般想到的是将所有元素保存起来,然后通过比较确定。 链表,树等等数据结构都是这种思路. 但是随着集合中元素的增加,我们需要的存储空间越来越大, 检索速度也越来越慢(O(n),O(logn))。
布隆过滤器(Bloom Filter)是 1970 年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。
原理
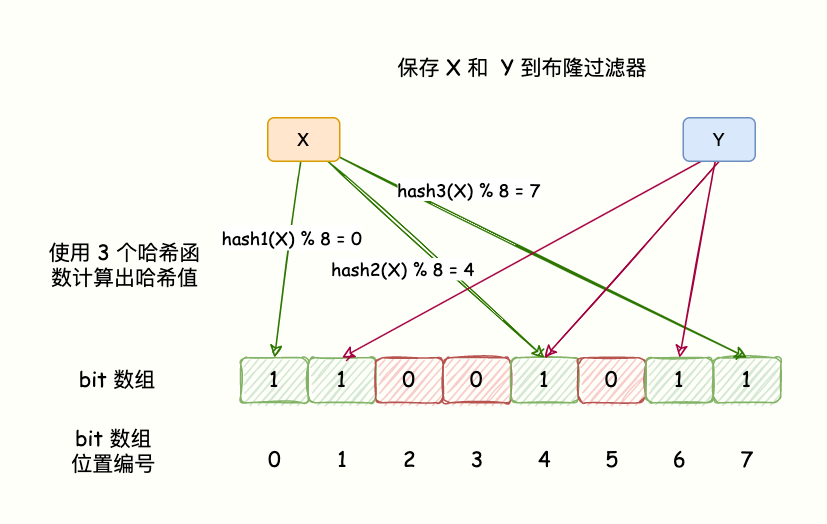
布隆过滤器由一个比特数组和一组哈希函数组成
布隆过滤器本质上可以理解为一个长度为 m 内容为 0 或 1 的列表。最初所有的值为 0。

为了将数据添加到布隆过滤器中,会提供 k 个哈希函数,利用哈希函数将数据映射到的位置的值设为 1。
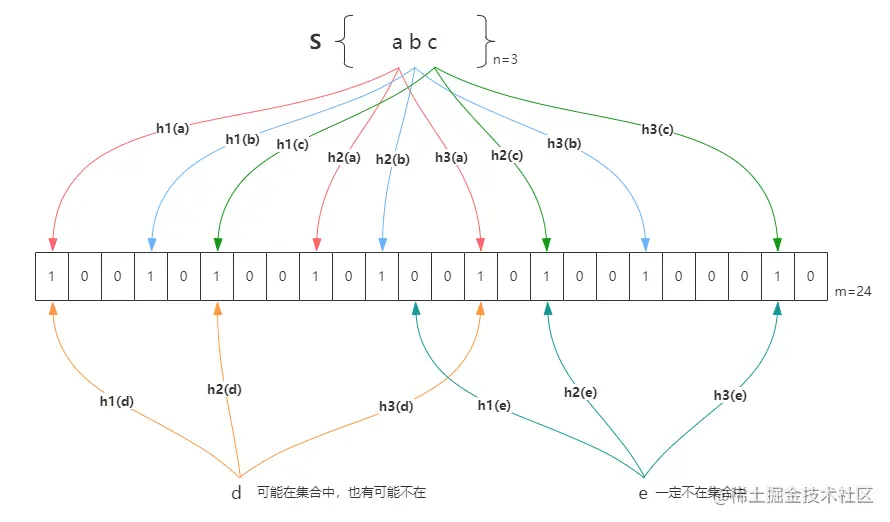
一次查找过程与一次插入过程类似,同样利用k个哈希函数对所需要查找的值进行散列,只有散列得到的每一个位的值均为1,才表示该值“有可能”真正存在;反之若有任意一位的值为0,则表示该值一定不存在。例如y1一定不存在;而y2可能存在。
优缺点
优点:
- 执行快
- 占用存储低
缺点:
-
误判率
布隆过滤器可能会误判某个不存在的元素为存在,但不会误判已存在的元素为不存在。
-
不支持删除操作
误判率的控制
- 位数组的大小(m):位数组越大,出现哈希碰撞几率越低,误判率就越低。
- 哈希函数的数量(k):哈希函数越多,误判率越低,但过多的哈希函数会增加计算开销。
- 插入元素的数量(n):插入的元素越多,误判率越高。
可以通过公式计算误判率:
$P=(1−exp(−\frac{kn}{m}))^k$
应用场景
- 缓存穿透防护:在缓存系统中,使用布隆过滤器判断请求的数据是否存在于数据库中,防止不存在的数据穿透缓存直接访问数据库。
- 黑名单过滤:在网络安全领域,用于快速判断IP地址、用户ID等是否在黑名单中。
- 数据库去重:在大数据处理过程中,用于快速判断某个记录是否已经存在于数据库中,避免重复数据的存储。
- 网页爬虫:在网页爬虫中,用于判断URL是否已经被抓取过,避免重复抓取。
- …
使用 redis 自带的布隆过滤器
布隆过滤器有两个基本指令,bf.add 添加元素,bf.exists 查询元素是否存在, 它的用法和 set 集合的 sadd 和 sismember 差不多。注意 bf.add 只能一次添加一个元素, 如果想要一次添加多个,就需要用到 bf.madd 指令。同样如果需要一次查询多个元素是否存在, 就需要用到 bf.mexists 指令。
-
创建布隆过滤器
1BF.RESERVE myfilter 0.01 1000myfilter是布隆过滤器的名称。0.01是期望的误判率。1000是预期要存储的元素个数。 -
添加元素到布隆过滤器:
1BF.ADD myfilter "item1" -
检查元素是否在布隆过滤器中:
1BF.EXISTS myfilter "item1"返回
1表示元素可能存在,返回0表示元素肯定不存在。 -
批量添加和检查元素:
-
批量添加:
1BF.MADD myfilter "item1" "item2" "item3" -
批量检查:
1BF.MEXISTS myfilter "item1" "item2" "item3"
-